Studentu HPC ceļvedis
Lai pievienotos LU HPC, vispirms jāizveido savienojums ar Latvijas Universitātes VPN tīklu.
- Gateway: vpn.lu.lv
- Lietotājvārds: LUIS Lietotājvārds
- Parole: LUIS parole
Kad savienojums ar Latvijas Universitātes VPN ir izveidots, var turpināt ar pieslēgšanos HPC serverim:
Jāpiemin, lai pieslēgtos serverim jāsazinās ar LU HPC uzturētājiem, lai izveidotu personīgu LU HPC kontu un mapīti, kur darboties:
Lietotājvārds un parole pievienojoties LU HPC nav LUIS, bet gan uzturētāju izveidots lietotājs uz HPC servera.
- ssh username@hpc.lu.lv
- Paroles ievade
Slurm komandrindas, kas var būt noderīgas iekš HPC servera:
- sinfo
- Pieejamie mezgli, partīcijas, mezglu statuss: piemēram, idle, alloc, down, drain.
- squeue
- Parāda visus aktīvos SLURM darbus uz HPC servera.
- JobID
- Partition
- Name
- User
- Time
- Node
- List
- Parāda visus aktīvos SLURM darbus uz HPC servera.
- squeue -u lietotajvards
- Apskatīt darbus, kādam konkrētam lietotājam
- scancel JOBID
- Aptur izveidoto SLURM darbu.
- scancel -u lietotajvards
- Aptur visus lietotāja aktīvos darbus
Darbu sākšana un ieiešana mezglos:
Piemēram, komanda:
srun --partition=gpu-jp --nodelist=node-gpu --mem=32G --cpus-per-task=16 --pty bash
- Izveido darbu, ieiet LU HPC gpu mezglā
- --mem=32G: piešķir darbam 32GB operatīvo atmiņu
- --cpus-per-task=16: piešķir darbam 16 CPU kodolus
- --pty bash: darbā ieiet ar interkatīvu režīmu
- Jāpiemin, ka šāda veida darbs vairāk var tikt lietots testēšanas režīmam, jo izejot no šī darba, izejot no servera šis darbs automātiski tiks pārtraukts:
- Testa komandas, lai noskaidrotu vai korekti ir sanācis pievienoties GPUmezglam, var palaist nvidia-smi, kas ļaus redzēt visas iespējamāsgrafiskās kartes.
Ilgstoša darbu izveide
Vispirms vajag izveidot vidi, kurā pieejamas bibliotēkas, var veidot savus Docker images, vai arī lietot pieejamus konteinerus.
Piemēram, lai izveidotu Singularity datni, kas satur PyTorch bibliotēku var palaist komandrindu, kas automātiski izveidos konteineri, kas saturēs PyTorch ar CUDA 11.8 versiju
- singularity pull docker://pytorch/pytorch:2.1.0-cuda11.8-cudnn8-runtime
Pēc konteinera ielādes lietotāja mapīte parādīsies fails ar nosaukumu:
- pytorch_2.1.0-cuda11.8-cudnn8-runtime.sif
Lai ieietu šajā Singularity failā ir jāpalaiž sekojošas komandrindas:
- module load singularity
- singularity exec --nv pytorch_2.1.0-cuda11.8-cudnn8-runtime.sif bash
- –nv jeb NVIDIA GPU ļauj konteinerim redzēt visas pieejamās mezgla videokartes.
Lai izveidotu ilgstošu darbu tiek lietots SBATCH, kas lietojams izveidojot shell skriptu:
Zemāk pievienots attēls ar piemēru darba izveidei, lietojot SBATCH: “run_pointnet.sh”
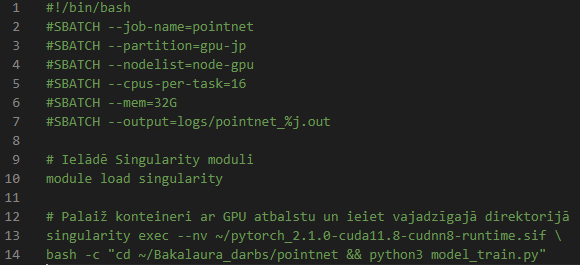
SBATCH argumenti ir līdzīgi kā iepriekš minētajā komandā srun:
srun --partition=gpu-jp --nodelist=node-gpu --mem=32G --cpus-per-task=16 --pty bash
Pēc skripta palaišanas ir iespējams aplūkot darbu ar komandrindām:
- squeue – validēt vai darbs ir sācies
- tail -f logs/pointnet_$jobid.out
- Ļaus sekot līdzi izvadītajiem “logs” no uzdevuma, piemēram, ja palaistajā skriptā ir print() komandas, tās izvade būs apskatāma šajā log failā
- Kā arī, ja darbs būs negaidītas darbības dēļ pārstājis darbību (nocrashojis), tad iemeslu varēs kļūdas ziņojums arī būs redzams log failā.
- Lai darbu apturētu tiek lietota komanda scancel $jobid
- jobid atrodams lietojot squeue
Sagatavoja Jānis Sausais 4.kursa students.